Googlebot, nas palavras do próprio Google:
Googlebot é o robô de rastreamento da Web do Google (também chamado de “indexador”). O rastreamento é o processo pelo qual o Googlebot descobre páginas novas e atualizadas para serem incluídas no índice do Google.
Devido à importância que tem o Googlebot é praxe dos provedores de hospedagem baixarem todas as defesas possíveis contra ele, fazendo uso do robots.txt para — quando necessário ou adequado — limitar a ação do bot em um determinado domínio. Exemplos de limites sensatos para a atuação do “bot” são:
- restringir a velocidade de rastreamento do domínio para evitar sobrecargas no servidor;
- restringir o acesso do bot a áreas que não se queiram indexadas pelo Google.
Quando falamos em baixar as defesas com relação ao Googlebot estamos nos referindo, entre outras coisas, à necessidade de evitar que o “bot” seja bloqueado no firewall por tentar acessar alguma coisa indevida: nem sempre lembramos de configurar um robots.txt detalhado o suficiente para garantir tráfego livre do programa de rastreamento somente por onde ele é desejado, ao mesmo tempo que o firewall deve estar configurado para bloquear qualquer visitante que faça algo indevido no site.
Em última análise, para o servidor o “bot” é um visitante.
Seções desta página
Como um servidor identifica o Googlebot
Acontece que para poder dar privilégios necessários ao Googlebot o servidor precisa saber distinguir entre ele e um outro visitante qualquer (que pode ser, por exemplo, um humano usando um dispositivo de navegação, um rastreador de outro mecanismo de indexação, ou mesmo um ladrão de conteúdo — também conhecido como scraper — tentando tirar proveito do trabalho alheio).
O protocolo HTTP prevê que todo “visitante” deve oferecer ao servidor uma informação chamada de user-agent, que é uma espécie de assinatura que permite ao site identificar que tipo de dispositivo está tentando acessar um determinado conteúdo. E é uma das coisas mais fáceis do mundo falsificar esta “assinatura”.
Isso significa que um programa mal intencionado pode fingir ser o rastreador do Google para tirar proveito de privilégios que normalmente estariam reservados apenas ao Googlebot legítimo, por exemplo nunca ser bloqueado no firewall.
Esse problema não é recente, e não existe uma solução universal para ele. Uma pesquisa no próprio Google vai mostrar dados muito antigos, de mais de dez anos, evidenciando a prática de disfarçar bots mal intencionados como se fossem o Googlebot. O uso mais comum desse truque costuma ter por objetivo acessar conteúdo (seja para copiar e republicar, seja para obter acesso livre a material restrito), mas em casos mais extremos esse expediente pode até ser usado para lançar ataques contra o site sendo rastreado, ou contra sites de terceiros.
A dificuldade de identificar o “bot” legítimo
Sabendo que o user-agent não é uma informação confiável resta (restaria) a opção óbvia de validar o IP do dispositivo que diz ser o Googlebot. Isso seria extremamente fácil de se fazer caso o Google divulgasse quais faixas de IPs seu rastreador usa para se conectar aos sites das pessoas.
Em vez disso o que o Google recomenda é até engraçado: que a cada requisição feita no servidor de algo ou alguém identificando-se como o “bot” sua legitimidade seja consultada (via consulta de DNS reverso para o IP) para ter certeza de que se trata mesmo do robô do Google, para só então permitir o acesso privilegiado.
Acontece que não é viável uma operação dessas, principalmente em se tratando de servidores menores, com capacidade de processamento mais reduzida, porque uma consulta de DNS reverso pode demorar uns milissegundos como pode demorar meio minuto, um minuto, talvez mais em casos mais longe do ideal. Ora, todos sabem que o bot valoriza muito a velocidade do site, e ninguém quer correr o risco de uma checagem adicional de DNS vir a prejudicar o desempenho do domínio nas SERPs!
A solução da Mônica


A Mônica, nossa robô que faz tudo o que ensinamos, tem uma solução para esse problema, em três subsistemas separados.
Identificação dos IPs legítimos do Google
O primeiro desses subsistemas é o que permite a identificação dos IPs do “bot” a despeito de o Google não divulgar a informação abertamente.
- Todos os acessos que são feitos a cada um dos sites de cada um dos clientes são registrados (claro).
- Periodicamente a Mônica passa nesses registros e analisa cada requisição (apenas o IP de onde ela partiu, e apenas se o user-agent for do Googlebot; nenhuma outra informação é utilizada para absolutamente nada, garantindo a privacidade dos clientes e dos visitantes).
- Caso a requisição tenha sido feita por um user-agent de Googlebot ela verifica se o IP realmente pertence ao rastreador legítimo, por meio de uma verificação de DNS.
- Caso o IP seja realmente do Googlebot ele vai para uma whitelist coletiva, compartilhada por todos os nossos servidores; a whitelist garante os privilégios necessários ao “bot” para que possa rastrear os domínios com velocidade e segurança.
Todos os clientes de VPSs sem cPanel participam deste crowdsourcing — uma vez que o uso de recursos de computação necessários para esta tarefa é irrisório.
Liberação dos IPs legítimos no firewall
O segundo subsistema simplesmente atualiza a lista de IPs permitidos no firewall — também conhecida por whitelist — de forma a garantir que os IPs legítimos do rastreador estejam sempre liberados.
Essa whitelist é, como dissemos antes, disponibilizada automaticamente a todos os clientes de máquinas Nitro Experience (esta tecnologia requer recursos avançados não disponíveis nos servidores mais antigos, ou com cPanel).
Bloqueio ativo de Googlebot falsificado
O terceiro subsistema também só está disponível para clientes de máquinas Nitro Experience, exclusivamente para os que solicitarem a ativação do recurso. Trata-se do bloqueio ativo dos falsos “bots” tendo por base o user-agent informado e o IP do dispositivo de navegação.
Caso o visitante informe um user-agent de Googlebot mas o IP não seja compatível com a whitelist colaborativa, então a conexão é finalizada imediatamente, impedindo assim que um impostor tenha a possibilidade de obter qualquer vantagem a que não tenha direito.
O bloqueio ativo do Googlebot falsificado não é padrão para todas as máquinas. Se o cliente quiser esta proteção extra para seus domínios deverá solicitar ao suporte técnico sua ativação gratuita.
Como bloquear o Googlebot falso pela Cloudflare
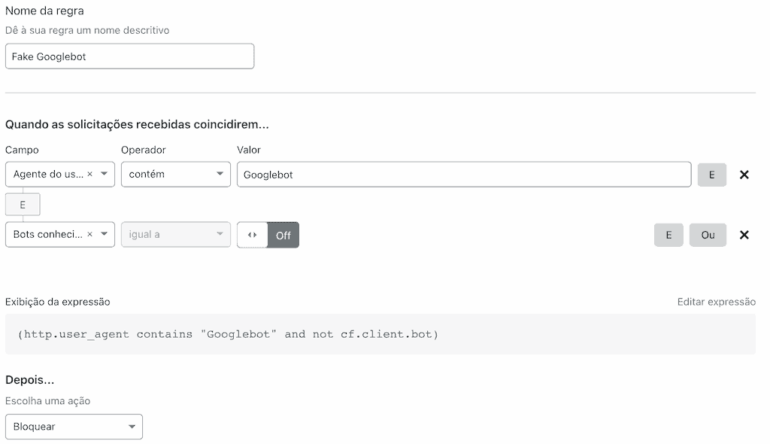
Bloquear o Googlebot falso em sites que usam o cache da Cloudflare é muito fácil, e muito eficiente. Basta acessar as configurações do domínio, Firewall, Regras do Firewall e criar uma nova regra (contas gratuitas têm direito a até cinco regras de firewall). Esta regra deve conter o seguinte:
(http.user_agent contains "Googlebot" and not cf.client.bot)
Ou em modo gráfico:
- Agente de Usuário, contém, Googlebot E
- Bots Conhecidos, igual a, Off
- Depois Bloquear

Resumo
O problema do Googlebot falsificado é antigo, tanto quanto o próprio Googlebot, e sua gravidade é discutível. Embora a possibilidade de se lançarem ataques utilizando “bots” falsificados seja um pouco mais remota, o roubo de conteúdo é absolutamente presente, e pode ser combatido facilmente utilizando as ferramentas que a PortoFácil oferece gratuitamente a seus clientes.